
Auteur original : Vitalik Buterin
Traduction et rédaction : DeFi 之道
Un grand merci à Ben DiFrancesco, Matt Solomon, Toni Wahrstätter et Antonio Sanso pour leurs retours et leur relecture.
La confidentialité reste l'un des principaux défis de l'écosystème Ethereum. Par défaut, toute donnée inscrite sur une blockchain publique est visible de tous. Cela concerne de plus en plus non seulement les transactions monétaires et financières, mais aussi les noms de domaine ENS, les POAP, les NFT et les jetons liés à l'identité (soulbound tokens), entre autres. En pratique, utiliser les applications Ethereum revient souvent à exposer des pans entiers de sa vie à quiconque souhaite les consulter ou les analyser.
La nécessité d'améliorer cette situation est aujourd'hui largement reconnue. Cependant, jusqu'à présent, les discussions sur la confidentialité se sont surtout concentrées sur un cas d'usage précis : les transferts privés d'ETH et des principaux jetons ERC-20 (souvent des transferts vers soi-même). Cet article explore les mécanismes et les applications d'une autre catégorie d'outils capables de renforcer la confidentialité sur Ethereum dans de nombreux autres scénarios : les adresses furtives (« stealth addresses »).
Qu'est-ce qu'un système d'adresses furtives ?
Imaginons qu'Alice veuille envoyer un actif à Bob. Il peut s'agir d'une somme en cryptomonnaie (par exemple 1 ETH ou 500 RAI) ou d'un NFT. Lorsque Bob reçoit cet actif, il ne souhaite pas que le monde entier sache qu'il en est le destinataire. S'il est impossible de masquer le fait même qu'un transfert a eu lieu (surtout pour un NFT unique), il est en revanche possible de dissimuler l'identité du bénéficiaire. Alice et Bob souhaitent également un processus de paiement aussi simple qu'aujourd'hui. Bob envoie donc à Alice (ou enregistre sur ENS) une sorte d'« adresse » codée, qui indique comment lui envoyer des fonds ; cette seule information doit suffire à Alice (ou à toute autre personne) pour effectuer le transfert.
Notons que cette confidentialité diffère de celle offerte par des outils comme Tornado Cash. Ce dernier permet de masquer les transferts d'actifs fongibles courants comme l'ETH ou les principaux jetons ERC-20 (bien qu'il soit surtout adapté aux transferts privés vers soi-même), mais il est peu efficace pour les jetons ERC-20 moins connus et incapable d'assurer la confidentialité des transferts de NFT.
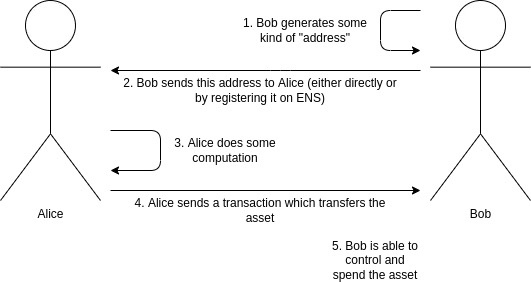
Flux de travail classique pour un paiement en cryptomonnaie. L'objectif est d'améliorer la confidentialité (personne ne doit savoir que Bob a reçu l'actif) tout en conservant le même processus.
Les adresses furtives offrent justement une telle solution. Une adresse furtive est une adresse que peut générer Alice (ou Bob), mais que seul Bob contrôle. Bob génère et garde secrète une clé de dépense, qu'il utilise pour produire une « méta-adresse furtive ». Il transmet cette méta-adresse à Alice (ou l'enregistre sur ENS). Alice peut alors effectuer un calcul à partir de cette méta-adresse pour générer une adresse furtive appartenant à Bob. Elle y envoie les actifs qu'elle souhaite lui transférer, et Bob en garde le contrôle exclusif. Lors du transfert, Alice publie sur la chaîne des données chiffrées supplémentaires (une clé publique temporaire) qui permettent à Bob de détecter que cette adresse lui appartient.
Autrement dit, les adresses furtives offrent à Bob le même niveau de confidentialité que s'il générait une nouvelle adresse pour chaque transaction, mais sans nécessiter la moindre action de sa part.
Le flux de travail complet d'un système d'adresses furtives est illustré ci-dessous :
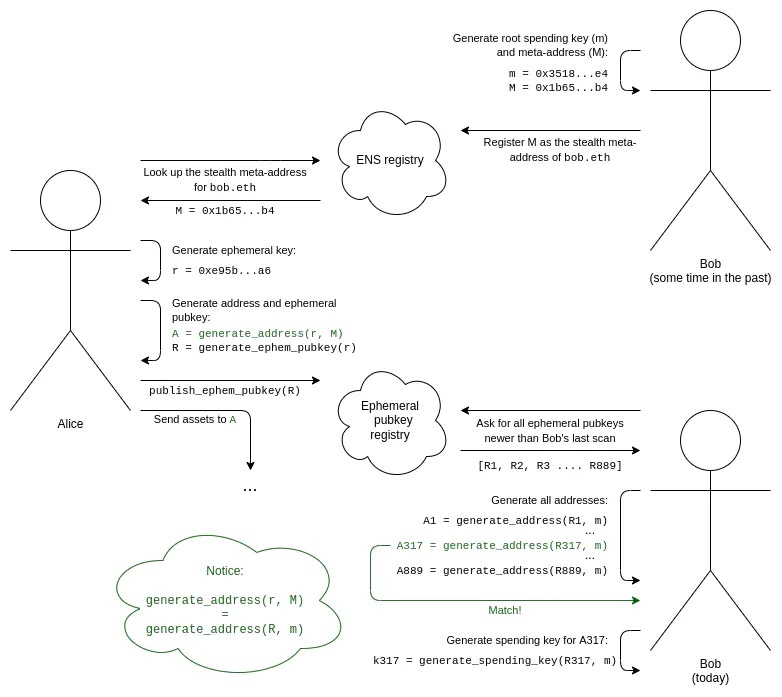
1. Bob génère sa clé racine de dépense (m) et sa méta-adresse furtive (M).
2. Bob enregistre M comme méta-adresse furtive pour bob.eth via un enregistrement ENS.
3. Supposons qu'Alice connaisse l'identité ENS de Bob (bob.eth). Elle interroge ENS pour récupérer sa méta-adresse furtive M.
4. Alice génère une clé éphémère qu'elle garde secrète et n'utilise qu'une seule fois (spécifiquement pour créer cette adresse furtive).
5. Alice utilise un algorithme qui combine sa clé éphémère et la méta-adresse de Bob pour générer une adresse furtive. Elle peut ensuite y envoyer des actifs.
6. Alice génère également la clé publique correspondant à sa clé éphémère, qu'elle publie dans un registre dédié (cette opération peut être effectuée dans la même transaction que l'envoi des actifs vers l'adresse furtive).
7. Pour découvrir les adresses furtives qui lui appartiennent, Bob doit scanner le registre des clés publiques éphémères. Il identifie ainsi toutes les nouvelles clés publiques éphémères publiées par quiconque depuis son dernier scan.
8. Pour chaque clé publique éphémère trouvée, Bob tente de la combiner avec sa clé racine de dépense pour générer une adresse furtive potentielle. Il vérifie ensuite si cette adresse contient des actifs. Si c'est le cas, Bob calcule la clé de dépense correspondante et la sauvegarde.
Ce processus repose sur deux applications distinctes du « masquage cryptographique ». Premièrement, il faut une paire d'algorithmes pour générer un secret partagé : l'un utilise l'élément secret d'Alice (sa clé éphémère) et l'élément public de Bob (sa méta-adresse), tandis que l'autre utilise l'élément secret de Bob (sa clé racine) et l'élément public d'Alice (sa clé publique éphémère). Plusieurs méthodes existent pour y parvenir ; l'échange de clés Diffie-Hellman, pilier de la cryptographie moderne, en est une illustration parfaite.
Cependant, un simple secret partagé ne suffit pas. Si l'on générait directement une clé privée à partir de ce secret, Alice et Bob pourraient tous deux dépenser depuis l'adresse. On pourrait s'arrêter là et demander à Bob de transférer les fonds, mais ce serait inefficace et réduirait inutilement le niveau de sécurité. C'est pourquoi on ajoute un mécanisme de « masquage de clé » : une paire d'algorithmes permettant à Bob de combiner le secret partagé avec sa clé racine, et à Alice de le combiner avec la méta-adresse de Bob. Ainsi, Alice peut générer l'adresse furtive, tandis que Bob peut générer la clé de dépense correspondante — le tout sans créer de lien public entre l'adresse furtive et la méta-adresse de Bob (ni entre deux adresses furtives distinctes).
Adresses furtives basées sur la cryptographie à courbe elliptique
Les adresses furtives basées sur la cryptographie à courbe elliptique ont été proposées initialement par Peter Todd en 2014 dans le contexte du Bitcoin. Leur principe de fonctionnement est le suivant (une connaissance des bases de la cryptographie sur courbe elliptique est supposée ; voir ici, ici et ici pour des tutoriels) :
• Bob génère une clé privée m et calcule M = G * m, où G est le point générateur convenu de la courbe elliptique. La méta-adresse furtive est l'encodage de M.
• Alice génère une clé éphémère privée r et publie la clé publique éphémère correspondante R = G * r.
• Alice peut calculer un secret partagé S = M * r, tandis que Bob peut calculer le même secret partagé S = m * R.
• Généralement, dans Bitcoin et Ethereum (y compris pour les comptes ERC-4337 bien conçus), une adresse est le hachage d'une clé publique servant à valider les transactions. Ainsi, une fois la clé publique calculée, on peut en déduire l'adresse. Pour calculer cette clé publique, Alice ou Bob effectuent le calcul P = M + G * hash(S).
• Pour calculer la clé privée correspondant à cette adresse, Bob (et lui seul) peut calculer p = m + hash(S). Cette approche, d'une grande élégance, satisfait à toutes les exigences énoncées plus haut !
Il existe même aujourd'hui une proposition d'amélioration d'Ethereum (EIP) visant à standardiser les adresses furtives sur le réseau. Elle prend en charge cette méthode tout en laissant aux utilisateurs la possibilité d'explorer d'autres approches (par exemple, permettre à Bob d'avoir des clés distinctes pour dépenser et visualiser, ou utiliser d'autres primitives cryptographiques pour assurer une résistance quantique). On pourrait penser : « Les adresses furtives, c'est simple en théorie, la mise en œuvre ne devrait être qu'un détail. » Le problème est qu'une implémentation réellement efficace doit relever plusieurs défis techniques majeurs.
Adresses furtives et frais de transaction
Imaginons qu’une personne vous envoie un NFT. Pour préserver votre vie privée, elle l’envoie à une adresse furtive que vous contrôlez. Après avoir analysé la clé publique éphémère sur la chaîne, votre portefeuille détecte automatiquement cette adresse. Vous pouvez désormais prouver la propriété de ce NFT ou le transférer. Mais un problème se pose : le solde ETH de ce compte est à zéro, ce qui rend impossible le paiement des frais de transaction. Même les payeurs de jetons ERC-4337 ne fonctionneraient pas, car ils ne s’appliquent qu’aux jetons ERC-20 fongibles. Et vous ne pouvez pas envoyer d’ETH depuis votre portefeuille principal vers cette adresse, car cela créerait un lien visible publiquement.
Une méthode « simple » existe pour résoudre ce problème : transférer des fonds via ZK-SNARKs pour payer les frais ! Cependant, cette approche consomme énormément de gaz, ajoutant plusieurs centaines de milliers d’unités à une seule transaction.
Une autre approche, plus astucieuse, consiste à faire appel à des agrégateurs de transactions spécialisés (les « chercheurs » dans la terminologie MEV). Ces agrégateurs permettent aux utilisateurs d’effectuer un paiement unique pour acheter un lot de « tickets » utilisables pour régler les frais de transaction sur la chaîne. Lorsqu’un utilisateur souhaite dépenser un NFT depuis une adresse furtive vide, il fournit l’un de ces tickets à l’agrégateur, codé selon un schéma d’aveuglement de Chaum. Il s’agit du protocole originel utilisé dans les systèmes centralisés de monnaie électronique préservant la vie privée, proposés dans les années 1980 et 1990. Le « chercheur » accepte le « ticket » et inclut gratuitement la transaction dans ses bundles jusqu’à sa validation dans un bloc. Étant donné le faible montant des fonds impliqués — et le fait qu’ils ne puissent servir qu’au paiement des frais — les problèmes de confiance et de régulation sont bien moindres que dans une implémentation « complète » d’un tel système de monnaie électronique.
Adresses furtives et séparation des clés de dépense et de visualisation
Supposons que Bob ne dispose pas d’une seule clé principale « racine » pour les dépenses, mais souhaite plutôt séparer ses clés : une clé racine pour les dépenses et une autre pour la visualisation. La clé de visualisation lui permet de voir toutes ses adresses furtives, mais ne lui autorise aucun retrait.
Dans le domaine des courbes elliptiques, cela peut être résolu grâce à une astuce cryptographique simple :
• L’adresse métamétrique de Bob M prend désormais la forme (K, V), encodée comme G * k et G * v, où k est la clé de dépense et v la clé de visualisation.
• Le secret partagé devient S = V * r = v * R, où r reste la clé éphémère d’Alice et R la clé publique éphémère qu’elle publie.
• La clé publique de l’adresse furtive est P = K + G * hash(S), et sa clé privée est p = k + hash(S).
Notez que la première étape cryptographique (génération du secret partagé) utilise la clé de visualisation, tandis que la seconde (l’algorithme parallèle d’Alice et Bob générant l’adresse furtive et sa clé privée) utilise la clé racine de dépense.
Cela ouvre de nombreux cas d’usage. Par exemple, si Bob souhaite recevoir des POAP, il peut fournir sa clé de visualisation à son portefeuille POAP (ou même à une interface web moins sécurisée) pour analyser la chaîne et consulter tous ses POAP, sans pour autant lui accorder le pouvoir de les dépenser.
Adresses furtives et analyse simplifiée
Pour faciliter l’analyse de l’ensemble des clés publiques éphémères, une technique consiste à ajouter une étiquette de visualisation à chacune d’elles. Une façon de l’intégrer au mécanisme décrit ci-dessus est d’utiliser un octet du secret partagé comme étiquette (par exemple, la coordonnée x de S modulo 256, ou le premier octet de hash(S)).
Ainsi, Bob n’a besoin d’effectuer qu’une seule multiplication sur courbe elliptique par clé publique éphémère pour calculer le secret partagé, tandis que le nombre de calculs plus complexes requis pour générer et vérifier l’adresse complète ne représente que 1/256 du total.
Adresses furtives et sécurité post-quantique
Le schéma décrit ci-dessus repose sur les courbes elliptiques, ce qui est efficace mais malheureusement vulnérable aux ordinateurs quantiques. Si ces derniers deviennent une menace concrète, il faudra migrer vers des algorithmes résistants aux attaques quantiques. Deux candidats naturels se dégagent : les isogénies de courbes elliptiques et les réseaux (lattices).
L'isogénie de courbes elliptiques est une construction mathématique distincte des approches précédentes. Ses propriétés linéaires permettent d'utiliser des techniques cryptographiques similaires, tout en contournant élégamment la création de groupes cycliques vulnérables aux attaques quantiques exploitant le problème du logarithme discret.
Le principal inconvénient de cette cryptographie réside dans l'extrême complexité des mathématiques sous-jacentes, qui pourrait masquer des vulnérabilités encore inconnues. L'an dernier, certains protocoles basés sur les isogénies ont été compromis, tandis que d'autres tiennent bon. Ses atouts majeurs sont la taille réduite des clés et la possibilité d'adapter directement de nombreuses méthodes issues des courbes elliptiques classiques.
Une 3-isogénie dans CSIDH. Source disponible ici.
Les réseaux (« lattices ») offrent une structure cryptographique radicalement différente, fondée sur des mathématiques bien plus simples que les isogénies, et capable de réaliser des opérations puissantes comme le chiffrement homomorphe complet (FHE). On peut concevoir des schémas d'adresses furtives sur cette base, même si la meilleure approche reste à déterminer. En revanche, les constructions basées sur les réseaux génèrent généralement des clés de taille plus importante.
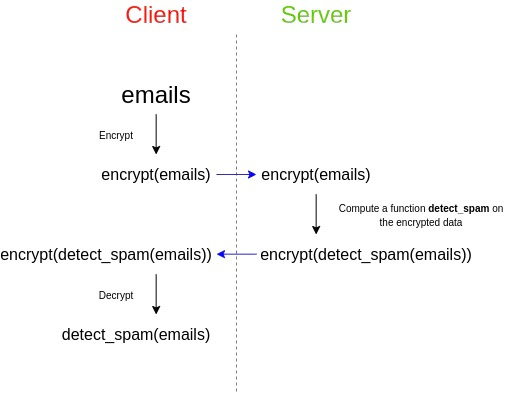
Le chiffrement homomorphe complet (FHE), une application des réseaux. Le FHE peut aussi faciliter les protocoles d'adresses furtives d'une autre manière : il permet à Bob de déléguer la vérification du solde d'une adresse furtive sur toute la chaîne, sans divulguer sa clé de visualisation.
Une troisième piste consiste à construire des schémas d'adresses furtives à partir de primitives génériques « boîte noire », c'est-à-dire des briques de base déjà nécessaires pour d'autres usages. La phase de génération du secret partagé correspond directement à un échange de clés, élément central du chiffrement asymétrique. La difficulté réside dans la conception d'un algorithme parallèle permettant à Alice de générer uniquement l'adresse furtive (et non la clé de dépense), tandis que Bob génère cette dernière.
Malheureusement, il est impossible de créer une adresse furtive avec des composants plus simples que ceux requis pour un système de chiffrement asymétrique. La preuve est simple : on peut construire un tel système à partir d'un schéma d'adresses furtives. Si Alice veut chiffrer un message pour Bob, elle peut envoyer N transactions, chacune vers une adresse furtive de Bob ou vers une sienne ; Bob déchiffre en observant quelles transactions il reçoit. Ce point est crucial : des preuves mathématiques établissent qu'on ne peut pas réaliser de chiffrement asymétrique avec de simples fonctions de hachage, alors que des preuves à divulgation nulle de connaissance, si. Par conséquent, les adresses furtives ne peuvent pas reposer uniquement sur des fonctions de hachage.
Voici une méthode utilisant des composants relativement simples : les preuves à divulgation nulle de connaissance, qui peuvent être construites à partir de fonctions de hachage et d'un chiffrement asymétrique à masquage de clé. L'« adresse méta » de Bob comprend une clé publique de chiffrement et un hachage h = hash(x), sa clé de dépense étant la clé privée correspondante x. Pour créer une adresse furtive, Alice génère une valeur c et publie son chiffrement (lisible par Bob) comme clé publique temporaire. L'adresse elle-même est un compte ERC-4337 dont le code valide les transactions en exigeant une preuve à divulgation nulle de connaissance attestant la possession de x et c tels que k = hash(hash(x), c) (où k est le code du compte). Connaissant x et c, Bob peut reconstruire lui-même l'adresse et son code.
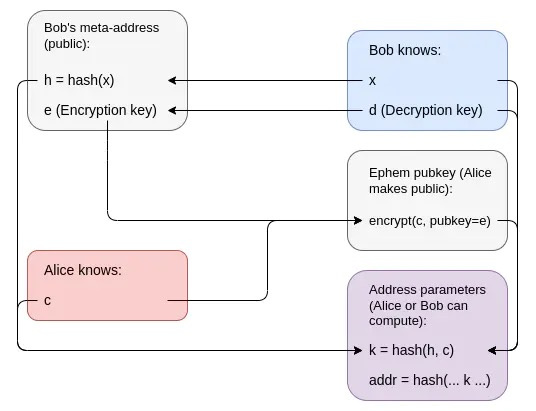
Le chiffrement de c ne révèle aucune information, et k étant un hachage, il ne divulgue pratiquement rien sur c. Le code du portefeuille ne contient que k, tandis que c reste privé, empêchant ainsi de remonter de k à h.
Cependant, cette méthode nécessite un STARK, dont la taille est conséquente. À terme, je pense que l'Ethereum post-quantique utilisera massivement les STARK pour de nombreuses applications. C'est pourquoi je plaide pour un protocole d'agrégation, comme décrit ici, permettant de regrouper tous ces STARK en un seul STARK récursif pour économiser de l'espace.
Adresses furtives, récupération sociale et portefeuilles multi-L2
Je suis depuis longtemps un partisan des portefeuilles à récupération sociale : des portefeuilles utilisant une signature multi-signature, où les clés sont réparties entre des institutions, vos autres appareils et vos amis. Une majorité de ces clés peut restaurer l'accès à votre compte, sauf si vous perdez votre clé principale.
Cependant, les portefeuilles à récupération sociale s'articulent mal avec les adresses furtives. Si vous devez restaurer votre compte (c'est-à-dire changer la clé privée qui le contrôle), vous devrez aussi modifier la logique de validation de vos N adresses furtives. Cela nécessiterait N transactions, avec un coût financier élevé, une perte de commodité et une atteinte à la confidentialité.
Des interrogations similaires se posent concernant l'interaction entre la récupération sociale et la multiplicité des protocoles de couche 2. Imaginons que vous déteniez des comptes sur Optimism, Arbitrum, Starknet, Scroll et Polygon. Pour des raisons de scalabilité, certains de ces rollups pourraient compter une dizaine d'instances parallèles, chacune hébergeant un de vos comptes. Dans ce scénario, modifier votre clé deviendrait une opération d'une complexité redoutable.
Changer les clés sur de multiples comptes répartis sur différentes chaînes représente un travail colossal.
Une première approche consiste à accepter que la récupération est un événement rare, et que son coût et sa complexité élevés sont tolérables. On pourrait, par exemple, utiliser un logiciel automatisé pour transférer ses actifs vers une nouvelle adresse secrète à intervalles aléatoires sur une période de deux semaines, afin de brouiller les liens temporels. Cette solution est toutefois loin d'être idéale. Une autre méthode serait de partager secrètement la clé racine entre les gardiens, plutôt que de passer par un contrat intelligent de récupération. Cela supprimerait cependant la possibilité de révoquer le droit des gardiens à intervenir, introduisant un risque à long terme.
Une approche plus sophistiquée fait appel aux preuves à divulgation nulle de connaissance (ZKP). Prenons le schéma ZKP décrit précédemment, mais modifions sa logique : au lieu de détenir directement k = hash(hash(x), c), le compte conserve un engagement (caché) vers une position k sur la chaîne. Pour dépenser depuis ce compte, il faut fournir une preuve ZK qui atteste (i) que vous connaissez la position sur la chaîne correspondant à cet engagement, et (ii) que l'��lément à cette position contient une valeur k (que vous ne révélez pas), et qu'il existe des valeurs x et c telles que k = hash(hash(x), c).
Cela permettrait à de nombreux comptes — y compris ceux répartis sur plusieurs protocoles de couche 2 — d'être contrôlés par une seule valeur k, stockée quelque part (sur la chaîne principale ou sur une couche 2). Modifier cette unique valeur suffirait alors à transférer la propriété de tous les comptes, sans révéler le moindre lien entre eux.
Conclusion
Les adresses furtives de base pourraient être déployées relativement rapidement et amélioreraient sensiblement la confidentialité des utilisateurs sur Ethereum. Leur adoption nécessite toutefois des adaptations côté portefeuilles. D'ailleurs, pour d'autres raisons liées à la vie privée, je pense que les portefeuilles devraient évoluer vers un modèle natif multi-adresses (par exemple, en générant une nouvelle adresse pour chaque application).
Cependant, les adresses furtives soulèvent des défis d'expérience utilisateur à long terme, comme la complexité de la récupération sociale. On peut, dans l'immédiat, accepter ces compromis — par exemple en reconnaissant qu'une récupération sociale impliquera une perte de confidentialité ou un délai de deux semaines pour publier progressivement les transactions sur différents actifs (délégable à un service tiers). Sur le long terme, ces problèmes sont solubles, mais l'écosystème des adresses furtives semble en effet reposer, à terme, sur les preuves à divulgation nulle de connaissance.