
杨强教授目前担任微众银行的首席人工智能官,香港科技大学计算机与工程系的讲座教授以及系主任,深耕于人工智能领域,在业内享有盛誉。其在人工智能领域做了大量开拓性的研究,从我们熟知的迁移学习到最近的联邦学习,近期更是出版国际上第一本在联邦学习方面的专著,而在迁移学习领域经过长时间的积累也有新书出炉。
1、联邦学习:数据不动 模型动
教授表示虽然AI在商业场景中依赖大数据发挥巨大价值,但是数据集较小、质量差的情况普遍存在,同时受到法律法规的性质约束,数据都以孤岛的形式分散在不同地方。
面对挑战环境,团队的研究集中在两方面,一是从大数据领域把知识迁移到小数据领域,实现不同的领域间的互通有无,解决数据小的问题,称之为迁移学习。二是将散落在不同地方的数据,在不将数据物理聚合的前提下,形成大数据的效果,称之为联邦学习。
教授首先围绕联邦学习作探讨,他认为Federated Learning 之所以翻译成联邦学习,从利益的角度出发,每一个数据集的意义是平等的,从隐私角度出发,我们不希望一个数据集拥有者能够看到另一个数据集包含的隐私,达到数据可用不可见的效果。故在联邦学习中采用的模式是数据不动,模型动。
在个人隐私与数据法规方面,全世界覆盖范围已相当广泛,欧盟出台《通用数据保护条例》(GDPR),设立各种条款保护个人隐私。国内近期人大刚刚出台数据隐私保护的草案,数据监管法案趋严。在这样场景下,联邦学习的诞生便非常应景。
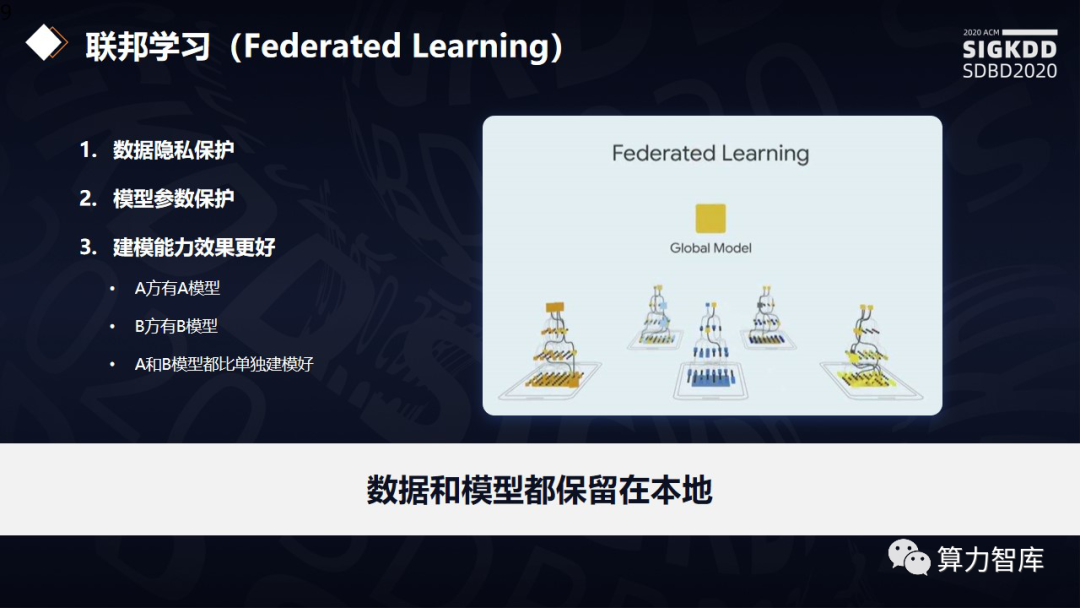
团队希望得到上图展示的效果,每一个地方都有自己的数据和界限,不会越界,建模时数据散落各地,合起来形成Globe模型。我们希望得到数据隐私保护、模型参数保护、要求建模的能力和效果变得更好。此前大量研究是在人工智能分布式建模,所有数据属于同一个属主,没有数据隐私问题,保证所有数据是同分布,并且是同构的。而在联邦学习的前提下,数据一定是异构的,存在隐私保护问题。
2、“羊吃草 ”模型
联邦学习和分布式建模的重大区别,前者是所有的数据都是属于一个属主,也就是说他没有数据隐私的问题,同时因为它可以去调配不同散落在不同服务器上的数据,所以可以保证所有的数据是同分布,并且是同构的。

那么在联邦学习的前提下,数据一定是异构的、异分布的并且有隐私保护,因而有区别。做一个简单的比喻,左边这就代表着过去我们AI的做法。假设我们在在喂养一只羊,就像在建立一个模型,过去我们把数据也就是草料运到羊所在的地方来建立,这是过去的做法。现在隐私保护的前提下,这些数据不能出本地,也就是草能不能出这些 farm,我们就带着羊去访问不同的地方,那么在这个过程中羊同样可以成长,并且数据不出本地,可以保证隐私不泄露。
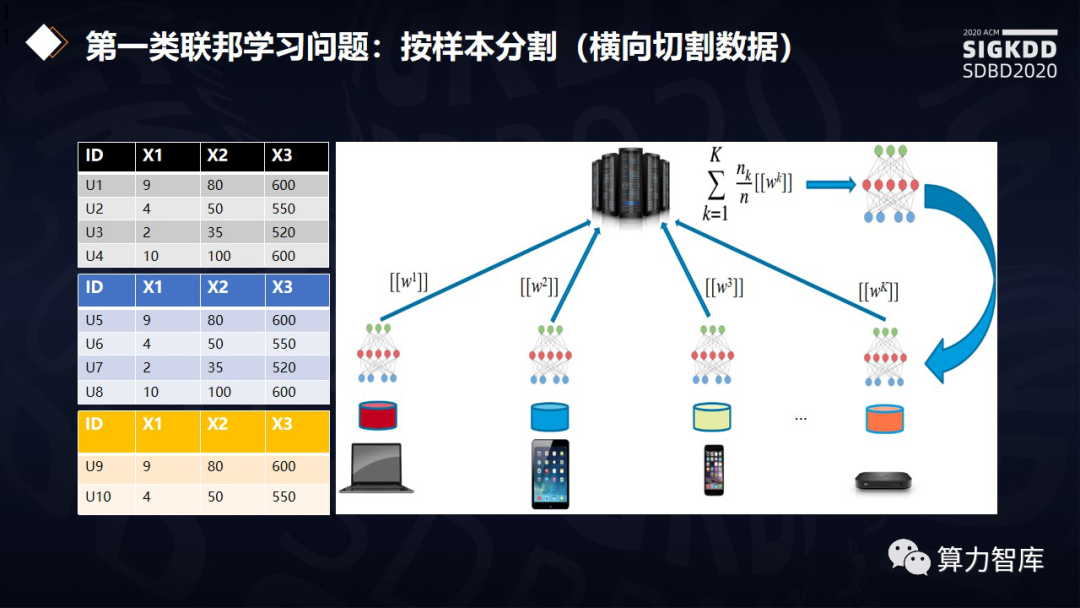
联邦学习问题分为两类,第一类按样本分割(横向切割数据)。我们可以想象所有的数据在虚拟空间,聚合为巨大的数据表。每一行都是一个样本,每一列都是一个特征。有一种分布数据的方法,每个终端有一部分样本的数据,可将数据的分布看成按照样本来切割的,即横向的切割。
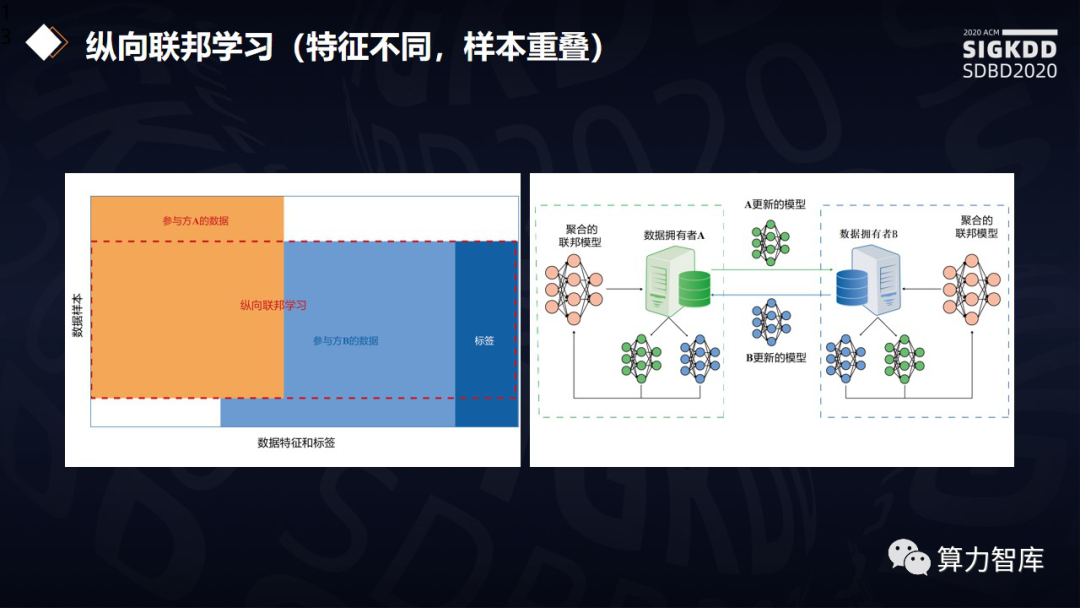
按特征来切割则为纵向切割。比方说有同一批病人到A和到B两家医院去看病,但是他们被检测的方式不同,分别是核酸和CT扫描,那么我们期望把数据形成大数据建模,按照特征来切割,即为第二类纵向切割。
横向也好,纵向也好,他们都要有共性,在样本或者在特征,万一他们没有共性,但是在语义层却有重叠,可以用迁移学习来解决问题。那么迁移学习的目的是说我们从一个领域可以把知识迁移到另一个领域,建模时可以站在巨人的肩膀上,比方说在数据一定的情况下,我们的效果就会更好;效果一定的情况下,我们用的数据量就会更少,举一反三,利用过去的知识来解决现在的问题。
杨强教授举一个特别的例子,如果我们在两个领域,红色和蓝色之间建立联邦学习的模型,不妨寻找共同的子空间,如果是在计算机视觉领域,用深度学习的多层深度的网络,靠近低层的网络,重叠的可能性较大,尤其在特征空间的重叠,则在该领域空间内,可以进行联邦学习建模。上层领域差别大,我们就可以先无视它们,将关注点放在共有的知识上,被称为联邦迁移学习。

谈及联邦学习落地,虽然联邦学习概念比较新,但是在金融、医疗领域已有广阔应用,杨强教授列举了一些案例。
如应用于反洗钱领域,帮助金融业高效准确的获取及分析风险平台数据;应用于信贷风控,帮助建立更大范围、更广泛、更靠谱的风险控制;在营销推荐领域,联邦系统可协助完成更好的个性化推荐;计算机视觉领域是AI的主战场,如不同工地的摄像头,通过联邦学习,实现用较高准确率识别违反安全的现象。
再保险公司可通过联邦计算基于不同保险公司的数来建立联合模型,将保险的权益个性化,保险公司之间建立横向联邦,保险公司和互联网公司之间进行纵向联邦,进行混合拓扑 ,实现个性化权益更为广泛的推广。
医疗方面,一个重要的需求是图像识别。如团队联合腾讯实验室治疗中风病患,通过医疗图像和检测医生的诊断获得数据,如果将不同医院数据联合起来,对病人而言特征会更多,那么纵向联邦被我们实现出来,效果就变得更好。数据表明,预测模型的平均准确率达到了80%以上,而在过去仅有60%左右。
4、联邦学习主战场图像识别
A I的一个主战场是视觉识别。杨强教授重点提及,在这方面可以用联邦学习做各类应用。在深圳有很多地产公司,他们都有建筑工地,每一个建筑工地都有很多摄像头来监控工人和仪器的安全。不同的建筑工地之间不希望交换数据,但是他们共同的一个愿望是能够把这种安全的或者违反安全的现象,用比较高的准确率给识别出来。因此他们也可以做联邦学习,我们用的这种联邦学习模式是横向联邦,它的效果也是非常的好。
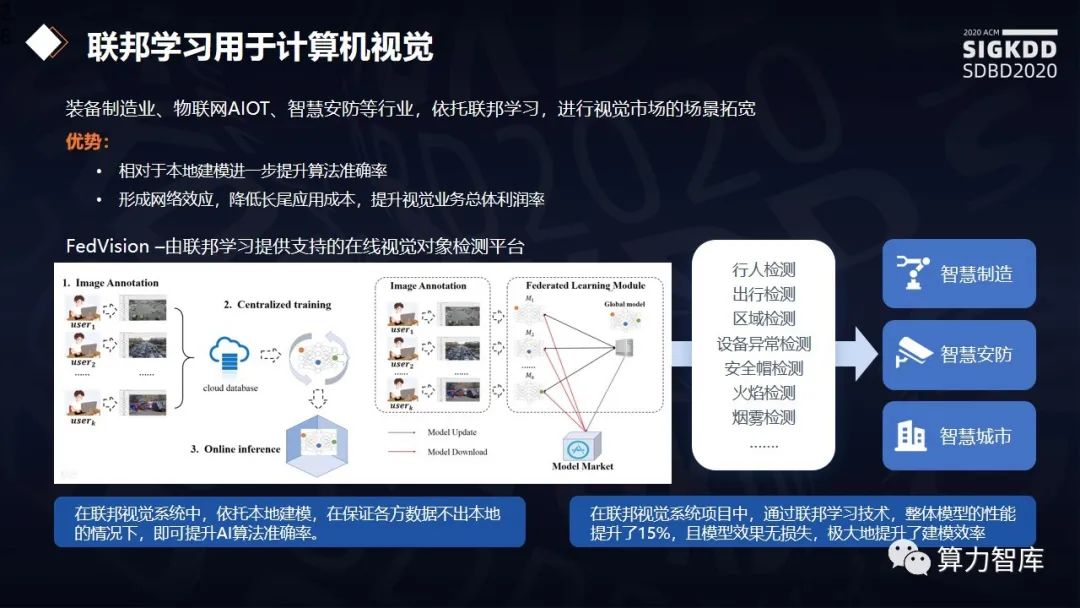
右边这就列举了一些它可以完成的更好的任务,比方说行人检测、设备异常检测、火焰检测、烟雾检测等等。我们可以看到在智慧城市智造安防都是非常有用的,在语音方面也可以用。微众是一家互联网银行,服务用户时间是7×24,所以必须要有很多机器人服务。机器人服务语音服务和语音识别当然是数据越多越好,比方说微众在四川有一个服务中心,在河南也有一个服务中心。这两个地方的口音是不一样的。在过去如果我们要让口音识别系统变得更好,就得把这两边的数据物理的运到一个数据中心来进行训练。现在用联邦学习,我们就可以做到数据不出本地,也可以训练一个更好的联合模型,不管你用的是四川口音还是河南口音都可以被识别出来。
5、联邦学习与健康码
杨强教授提及了他们最新关于健康码的研究。国内在疫情上非常有效的管控措施来自于健康码。国内公民坐飞机、进入办公室大楼大厦都要出示健康码,健康码实际上是在做数据库的查询与个人轨迹追踪,或多或少的会暴露你的隐私。你去过何处,接触过何人?这些隐私数据在紧急公共卫生事件下,大家是不在乎给出去的。但是若以后如果出示健康码变成一种常态,我们会在乎隐私的,这个时候联邦学习就需要登场解决问题了。杨强教授团队最近也是提出了一个新的专利。
6、联邦学习:对抗攻击的应对
部分研究者特别关心一些对抗攻击,如联邦学习、迁移学习是由多方计算组成的,其中一方如果是坏人或是好奇心过重的人,在不加任何加密保护的前提下,可以使另一方重现原始数据,即深度泄露攻击。
团队的一项研究表明虽然有可能破解,但是如果使用联邦学习,并且在每一方我们都建立合适的模型,效率与隐私安全可以得到保障。团队在理论上证明可以在完全不影响模型效果的同时,完全防御深度泄露攻击。
最后,杨强教授总结道,联邦学习刚刚起步,之所以有生命力,是因为社会的需求、公众对隐私的呼声、政府的监管及海量商企的需求。因为如果只有监管和公众的呼声,而技术上没有任何对应的办法,技术就会陷入停滞,现在所做的AI和大数据的研究便无从落地。所以本着这样的心态,团队研究联邦学习。为将新获得的收益公平分发,使参与者持续处在生态中,团队也在积极设计合适的联盟机制与生态。
联邦学习不仅仅是技术,更是一个生态的建立,生态的建立离不开开源。之所以我们重视开源,因为安全的第一准则是大家所获得的工具必须透明。基于这样的理念,团队发布了世界上第一个开源平台——FATE,提供几乎所有主流的机器学习算法,提供联邦学习平台,并允许使用各种多方安全计算的协议,提供包括审计在内的服务。



专注区块链、人工智能、大数据等领域深度原创报道、调研报告、产业咨询研究的数字经济智库平台。用专业化的视角为您解读分析数字科技的最新热点与主题,挖掘数字经济与实体行业融合、迭代的应用价值与资本价值
 119
111
110
107
90
119
111
110
107
90






